

구글이 화요일에 발표했다. 뤼미에르“현실적인 비디오 생성을 위한 시공간 확산 모델”이라는 AI 비디오 생성기 함께 제공되는 사전 인쇄 시트. 하지만 농담하지 마세요. 롤러 스케이트 사용, 자동차 운전, 피아노 연주와 같은 어리석은 시나리오에서 귀여운 동물의 비디오를 만드는 데 훌륭한 역할을 합니다. 물론 더 많은 일을 할 수 있지만 아마도 지금까지 가장 발전된 텍스트-동물 AI 기반 비디오 생성기일 것입니다.
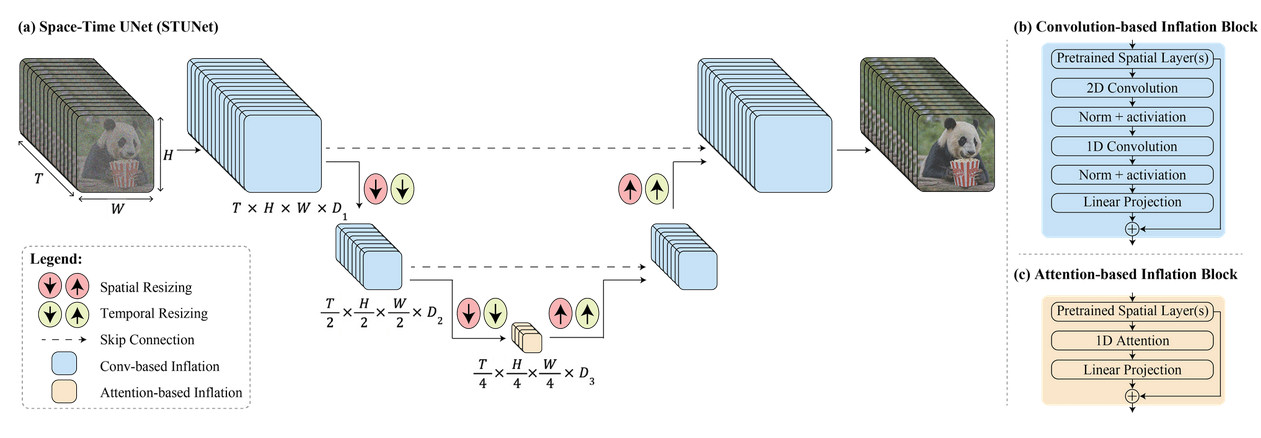
Google에 따르면 Lumiere는 독특한 구조를 사용하여 동영상의 전체 길이를 한 번에 생성합니다. 또는 회사에서 말했듯이 “우리는 모델의 단일 패스를 통해 비디오의 전체 시간 지속 시간을 한 번에 생성하는 Space-Time U-Net 아키텍처를 제공합니다. 이는 긴 비디오를 조립하는 기존 비디오 모델과 대조됩니다. 거리 키 프레임에 이어 초고시간 해상도 – “글로벌 시간 일관성을 달성하기 어렵게 만드는 접근 방식입니다.”
일반인의 관점에서 볼 때 Google의 기술은 공간(동영상 속 사물이 있는 위치)과 시간(동영상 전체에서 사물이 어떻게 움직이고 변화하는지)의 측면을 동시에 처리하도록 설계되었습니다. 따라서 많은 작은 부분이나 프레임을 연결하여 비디오를 만드는 대신 처음부터 끝까지 전체 비디오를 하나의 원활한 프로세스로 만들 수 있습니다.
Google에서 공개한 “Lumiere: A spatio-temporal 확산 모델 for video Generation” 기사와 함께 제공되는 공식 홍보 영상입니다.
Lumiere는 예시와 함께 멋지게 정리된 다양한 파티 트릭도 수행할 수 있습니다. 구글 데모 페이지. 예를 들어, 텍스트-비디오 변환(작성된 프롬프트를 비디오로 변환), 스틸 이미지를 비디오 클립으로 변환, 참조 이미지를 사용하여 특정 스타일의 비디오 생성, 텍스트 기반 프롬프트를 사용하여 일관된 비디오 편집 적용 등을 수행할 수 있습니다. 만들다 영화 부문 이미지의 특정 영역을 이동하여 영상을 표시함으로써 com.inpainting 능력(예: 사람이 입는 옷의 종류를 바꿀 수 있음)
Lumiere 논문에서 Google 연구원들은 AI 모델이 1024 x 1024 픽셀의 해상도로 5초짜리 비디오를 생성한다고 보고했는데, 이를 “저해상도”라고 표현합니다. 이러한 한계에도 불구하고 연구원들은 사용자 연구를 수행했으며 Lumiere의 출력이 AI 기반 비디오 합성 모델보다 바람직하다고 주장했습니다.
훈련 데이터에 관해 구글은 루미에르에 공급된 비디오를 어디서 얻었는지 밝히지 않았습니다. “우리는 우리 자신의 T2V 장치를 훈련하고 있습니다.” [text to video] 텍스트 캡션과 함께 3천만 개의 비디오가 포함된 데이터 세트를 모델링합니다. [sic] 비디오는 16fps(5초)에서 80프레임 길이입니다. 기본 모델은 128 x 128에서 훈련되었습니다.”
AI로 생성된 비디오는 아직 초기 단계이지만 지난 몇 년 동안 품질이 향상되었습니다. 2022년 10월에는 Google이 처음으로 공개한 이미지 합성 모델인 Imagen Video에 대해 다루었습니다. 입력된 프롬프트에서 초당 24프레임의 짧은 1280 x 768 비디오를 생성할 수 있지만 결과가 항상 일관되지는 않았습니다. 그 전에 Meta는 자체 AI 비디오 생성기인 Make-A-Video를 선보였습니다. 작년 6월, Runway의 Gen2 비디오 합성 모델을 통해 텍스트 프롬프트에서 2초짜리 비디오를 생성하여 초현실적이고 풍자적인 광고를 만들 수 있었습니다. 그리고 11월에는 정지 이미지에서 짧은 클립을 만들 수 있는 Stable Video Diffusion에 대해 다루었습니다.
AI 회사는 종종 귀여운 동물의 비디오 생성기를 제공합니다. 일관되고 왜곡되지 않은 인간을 생성하는 것이 현재 어렵기 때문입니다. 특히 우리 인간(당신은 인간이죠?)이 사람 신체의 결함이나 움직이는 방식을 잘 알아차리는 데 능숙하기 때문입니다. AI가 생성한 윌 스미스가 스파게티를 먹는 모습을 보세요.
Google의 예(직접 사용하지 않음)로 판단하면 Lumiere는 다른 AI 기반 비디오 제작 모델보다 성능이 뛰어난 것 같습니다. 그러나 Google은 AI 연구 모델을 가슴에 가까이 두는 경향이 있기 때문에 대중이 언제 직접 시험해 볼 기회를 얻을 수 있을지 확신할 수 없습니다.
언제나 그렇듯이, 텍스트-비디오 합성 모델의 성능이 더욱 향상되는 것을 보면 우리는 생각하지 않을 수 없습니다… 미래에 미치는 영향 미디어 요소를 공유하는 온라인 사회와 “현실적인” 비디오가 일반적으로 카메라에 포착된 실제 상황에서 실제 사물을 표현한다는 일반적인 가정을 위한 것입니다. Lumiere의 더욱 유능한 미래 비디오 합성 도구를 사용하면 사기성 딥페이크를 매우 쉽게 만들 수 있습니다.
이를 위해 연구원들은 Lumiere 논문의 “사회적 영향” 섹션에 다음과 같이 썼습니다. “이 작업의 주요 목표는 초보 사용자가 창의적이고 유연한 방식으로 시각적 콘텐츠를 만들 수 있도록 하는 것입니다. [sic] 그러나 당사의 기술을 사용하여 가짜이거나 유해한 콘텐츠를 생성하는 것은 오용의 위험이 있으며, 안전하고 공정한 사용을 보장하기 위해서는 편견 및 유해한 사용 사례를 탐지하는 도구를 개발하고 구현하는 것이 필요하다고 믿습니다.

이문열은 bsnewspaper.com의 필진으로 뉴스, 정치, 경제, 기술, 스포츠, 엔터테인먼트, 라이프스타일 등 다양한 분야의 소식을 다룹니다. 독자들이 중요한 이슈를 쉽게 이해할 수 있도록 명확하고 균형 잡힌 보도에 중점을 두고 있으며, 유용한 정보와 시의성 있는 내용을 전달합니다. 또한 현재의 주요 사건과 독자들의 관심사에 맞는 이야기를 알기 쉽게 풀어내는 데 힘쓰고 있습니다.